Using AI generated content from ChatGPT? You could get a Google penalty! If you use AI writing tools for blogging and think that this is the best new way for…
Did you know that Google offers free SEO tools for site audit which you can use to check your site’s technical SEO and improve site visibility in Google search engine…
Group buy SEO tools are a popular way for the site owner to access premium keywords research software like Moz, SEMrush, Ahrefs, and many more at discounted prices to optimize…
Is your site name appearing wrong in Google search? Did you know there is a better way in which you can suggest your site name to Google using structured data….
E-E-A-T has replaced the E-A-T in Google search quality rater guidelines. EEAT is the new way website owners need to plan their sites for Google SEO if they wish to…
Did you know that ahrefs free account is available via ahrefs Webmaster tools for your own sites? While Google Webmaster tools, now called Google search console have been freely available…
Now you can lazy load images quickly using this code. Lazy Loading Images is essential If you want to fix your site core web vitals statistics and increase site speed…
Google has released the Core Web Vitals report in Google Webmaster Tools which expresses the quality signals that they use to improve User experience on the web. The aim of…
If you are using the amazing Yoast SEO WordPress Plugin, how to noindex archive subpages from tags and categories so they can be blocked from the Google Index. You have…
What are the benefits of nofollow backlinks? If you see its advantages, they are not junk anymore. In fact, they can be valuable in some ways. This article is inspired…
Now you can learn SEO through free Moz SEO courses. Moz has made its excellent SEO training courses available for free at the Moz academy for a limited time period…
Do you want to recover lost link juice from deleted subdomains? Many times we create subdomains to publish related content and over time many of us have had to delete…
Want to change WordPress permalinks structure? It can lead to 404 errors and huge SEO challenges if not done the right way. However, it is clear that if you have…
Here are the best page speed tests, powerful tools to measure site speed and page loading times online, to help you identify slow pages and understand strategies to increase Page…
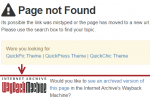
Would it not be nice if you could have links on 404 Error pages pointing to Wayback machine Archive.org links on how the pages looked like in the past. Of…
How can you set up 410 Gone Error pages using .htaccess redirects? 410 error is an HTTP server response to signify that the particular webpage is gone forever, is permanently…
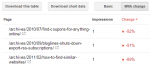
A lot of us hit with Google Panda and Penguin penalties want a fast reliable way to find web pages losing traffic the most. This helps webmasters identify the web…
Google has informed webmasters that they now consider HTTPS secure sites as a ranking signal for Google algorithms. HTTPS stands for Hypertext Transfer Protocol Secure and is a protocol for…
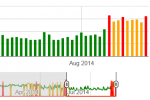
When is the next Panda or penguin update starting? There are several tools that track Google algorithm changes by analyzing search engine rankings and search results for thousands of websites…
How can you track adjusted bounce rate in the new Universal Analytics by Google Analytics. ABR is short for adjusted bounce rate and is a recommended solution by Google to…